En oficinas se pueden encontrar equipos llamados scanners, aparatos que sirven para escanear documentos, su contenido en papel, y pasarlo a un formato electrónico.

También podemos encontrar este aparato para escanear documentos en las impresoras multifunción. Si es así simplemente podemos poner el documento que queremos escanear y seguimos las instrucciones del equipo escaner que estemos usando (eso varía dependiendo de la marca y tipo de fabricante).
Pero si no tenemos ese tipo de equipo, podemos usar nuestro teléfono móvil o tablet, incluso una cámara de fotos o la webcam.
¿Cómo hacemos eso?
Bastará con que pongamos el documento sobre una mesa, abramos la cámara del móvil y tomemos una foto lo más nítida posible del documento. Guardamos la foto y la transferimos a nuestro ordenador.
El resultado va a ser un archivo de imagen. Ahora lo que queremos es poder extraer el texto que contiene esa imagen. Es decir el contenido del documento original.
Para esto vamos a echar mano de un software en Linux que nos permiten escanear documentos a través de un reconocimiento de texto.
La primer aplicación es gscan2pdf. Esta abre el documento en formato imagen y lo convierte al formato PDF que luego podemos leer usando alguna de las sugerencias que mostramos en el artículo: «5 excelentes aplicaciones para leer libros electrónicos en Ubuntu».
Para instalar gscan2pdf vamos a abrir una terminal y en ella escribiremos el siguiente comando:
sudo apt install gscan2pdf
Dependiendo de la distro de Linux que tengamos puede pesar más o menos MB. En el caso de KDE Neon el software (unos 239 MB) se instala con muchas dependencias necesarias para trabajar sin preocuparnos por nada más.
Lo segundo que necesitamos instalar es el controlador de reconocimiento de textos en español. Para esto vamos a escribir en la terminal:
sudo apt install tesseract-ocr-spa
Bien ya estamos equipados para comenzar con la tarea de escanear documentos en Linux.
Para el ejemplo, tomé una foto de una página de un libro. El texto está en español. La transferí a mi laptop y ahora vamos a ver cómo extraer el texto de la imagen.
Abrimos gscan2pdf y usamos la opción para abrir la imagen, como se ve aquí:
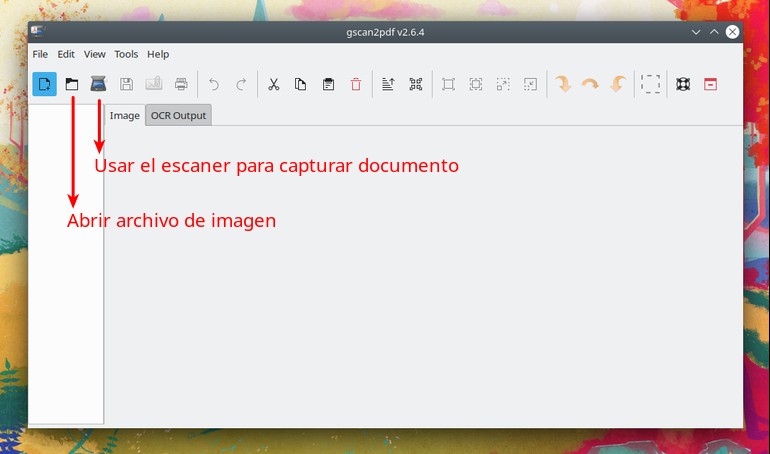
Una vez que el software nos muestra en pantalla la imagen seleccionada, ahora tenemos que indicarle que queremos extraer el texto. Para esto vamos al menú superior, elegimos «Tools», y en el desplegable haremos clic en «OCR».
Tenemos que esperar unos segundos (esto depende de la cantidad de imágenes que hayamos abierto). A continuación tenemos que hacer clic en la pestaña «OCR Output», y allí vamos a tener disponible una presentación del texto capturado del documento.
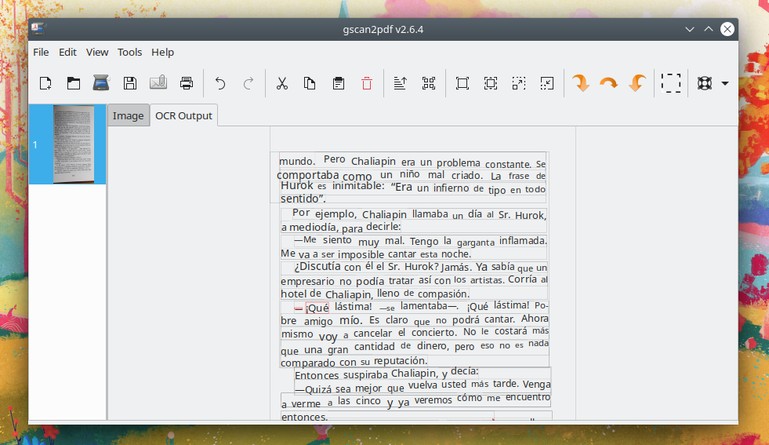
Gscan2pdf nos permite corregir ese texto si vemos que hay algo que no está correctamente escrito. Para eso haremos clic en la(s) palabra(s) que deseemos corregir, y escribimos el texto correcto.
¿Estamos satisfechos con el resultado? Entonces podemos guardar el archivo en el formato que necesitemos. Los dos más comunes son: PDF y TXT (entre otros tantos).
Hay otras opciones para realizar escaneo de documentos y pasarlos a texto. Pero lo bueno de Gscan2pdf es que está disponible en casi la totalidad de las distribuciones de Linux.